|
I am a Founding Engineer & Head of AI at an early-stage start-up in San Francisco working on large-language models. Before that, I was working on computer vision and reinforcement & imitation learning for robot manipulation at Covariant.ai. I graduated from the MSR program at the Robotics Institute at Carnegie Mellon University, where I was glad to have been co-advised by Katerina Fragkiadaki & Oliver Kroemer.I also got a Bachelors in Mechanical Engineering and a Masters in Computational Engineering from the Technical University Darmstadt. Google Scholar / Twitter / GitHub / LinkedIn |

|
|
|
 |
In this work, we present a fully-convolutional shape completion model, F-CON, which can be easily combined with off-the-shelf planning methods for dense packing in the real world. We also release a simulated dataset, COB-3D-v2, that can be used to train shape completion models for real-word robotics applications, and use it to demonstrate that F-CON outperforms other state-of-the-art shape completion method. |
 |
We propose methods for leveraging autoregressive models to make high confidence 3D bounding box predictions, achieving strong results on SUN-RGBD, Scannet, KITTI, and our new dataset, COB-3D. We release this simulated dataset which highlights new types of ambiguity that arise in real-world robotics applications. |
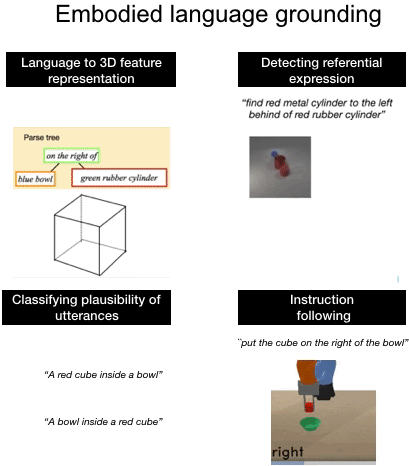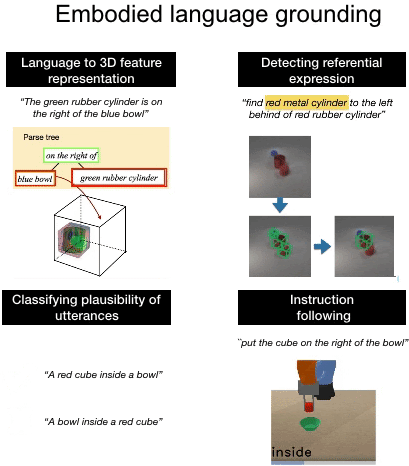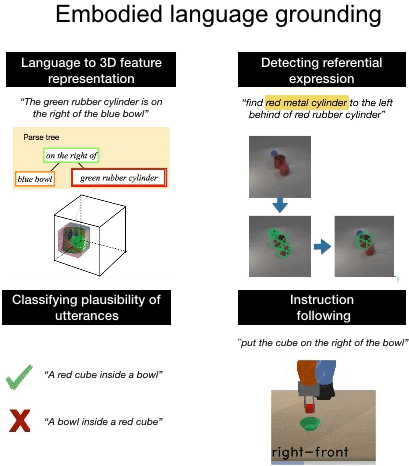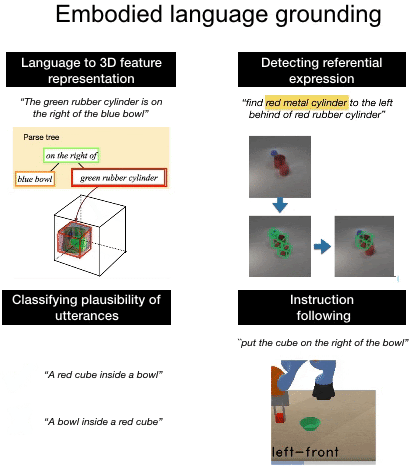 |
We introduce a computational model of simulation semantics that associate language utterances to 3D visual abstractions of the scene they describe. We encode the visual abstractions via 3-dimensional visual feature maps that we obtain via view prediction from different RGB images of the scene in a self-supervised manner. |
 |
We propose a graph-structured state representation for visual imitation learning. We show how we can leverage different visual entities of various granularities to obtain a state representation that can be used for reinforcement learning to learn manipulation skills within a few minutes of real-life policy rollouts. |
 |
We show how we can use synthetically generated image data from only a few background-subtracted ground-truth images to build instance-specific object detectors robust to partial occlusions. Further, we demonstrate how we can use these detectors to imitate human demonstrations of manipulation tasks in a sample-efficient manner, where the overall imitation learning process takes less than 10 minutes. |
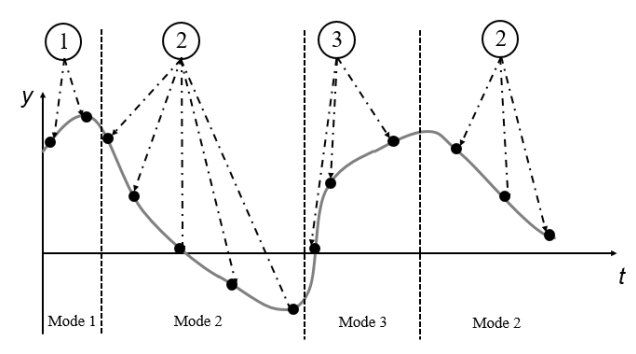 |
This work is about inferring dynamical modes of a given trajectory in a non-parametric fashion. Simply said, the algorithm tries to fit multiple linear segments within the trajectory where the number of fitted segments does not have to specified, but is inferred as well by using a non-parametric dirichlet prior. |
|
|
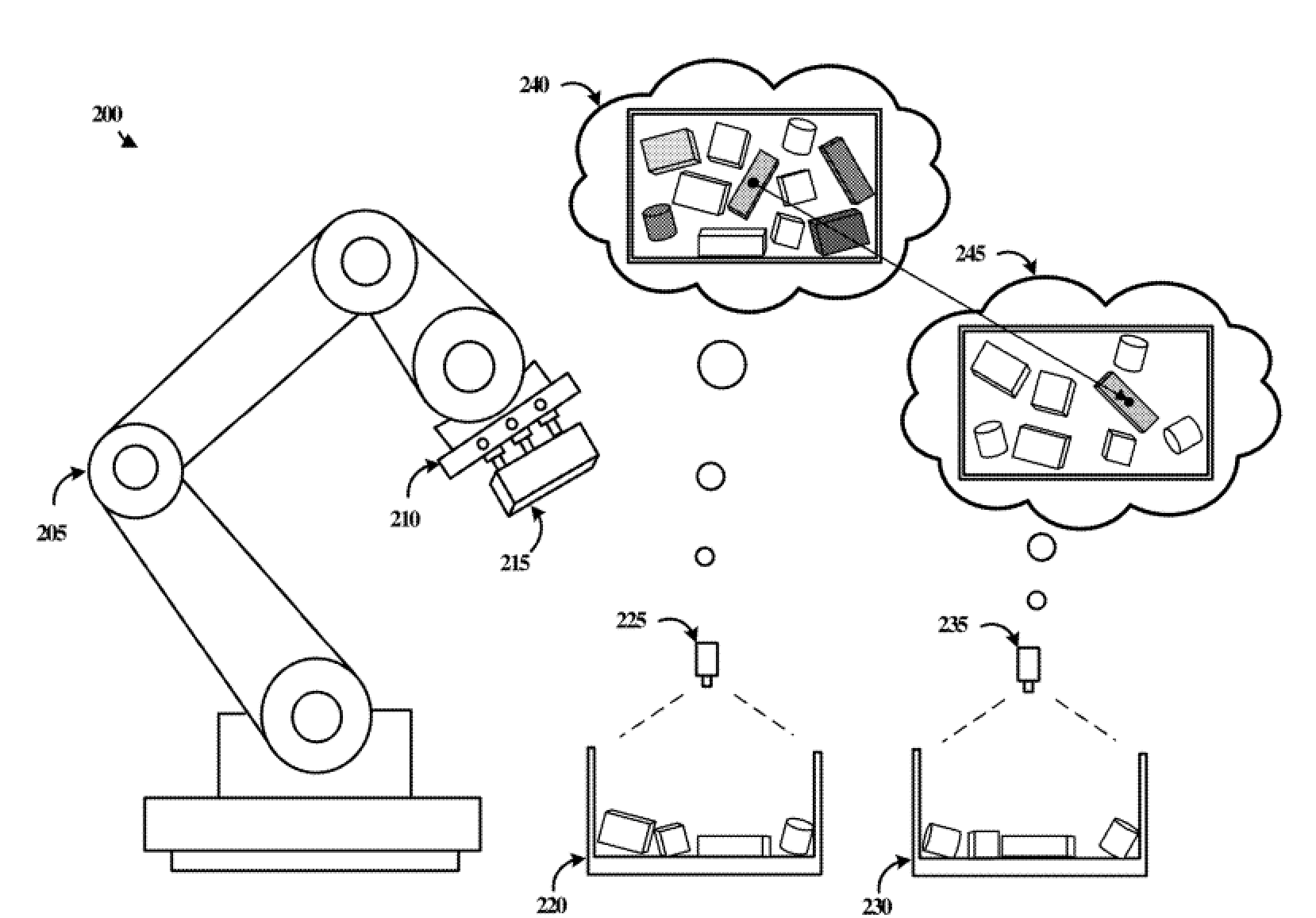 |
The idea here is the following: We have a bin from which we wish to pick items. For every pick, we want to avoid picking items which we have failed to pick before. However, because items in the bin might move around between subsequent picks, it is not obvious how to correlate objects across different picks to keep track of the failure count. In this work, we introduce a deep learning based approach to predict correspondences of objects given two scenes. |
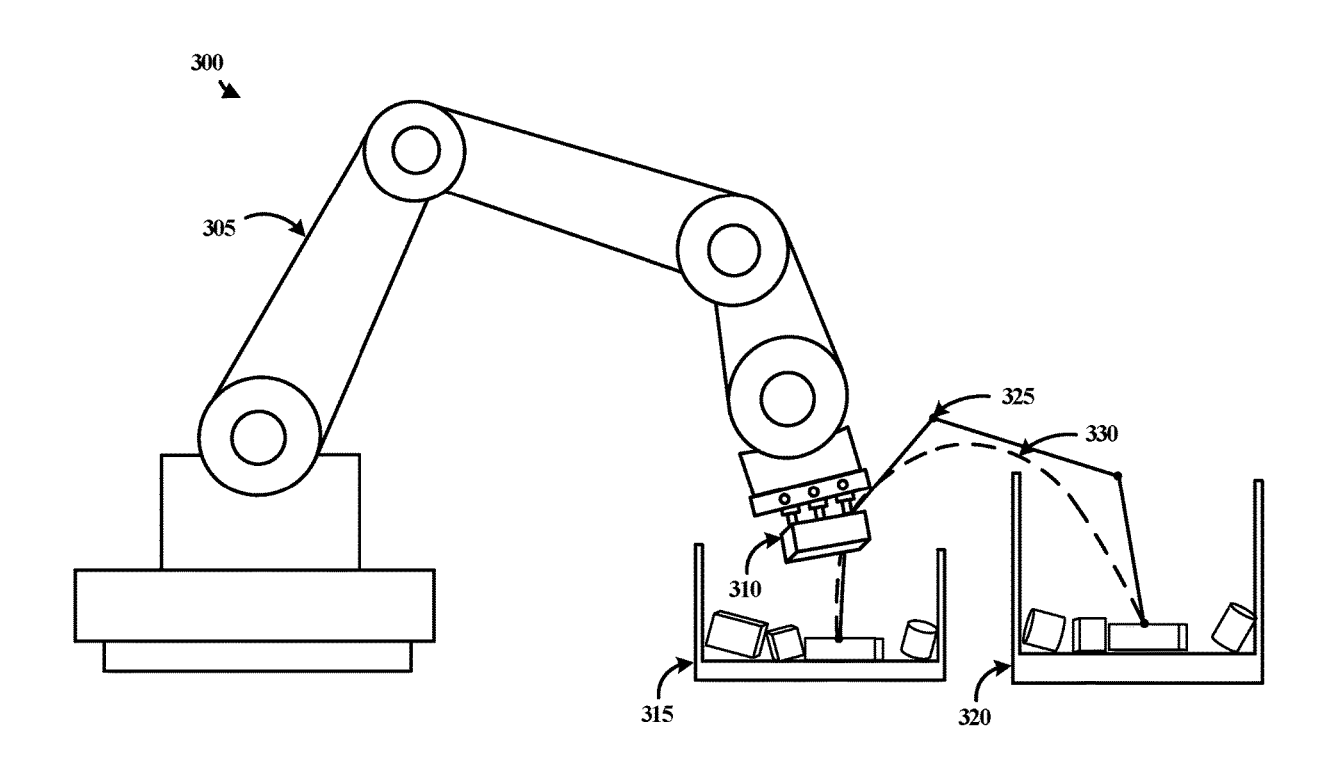 |
We use use deep neural networks to quickly predict optimized robotic arm trajectories according to certain constraints in pick & place application for industrial robotics. |
|
|
 |
In my Master thesis I talk about how we can leverage visual imitation learning for robot manipulation. More specifically, I focus on how we can use state-of-the-art computer vision models and reinforcement learning to imitate an expert trajectory from just a single demonstration. |
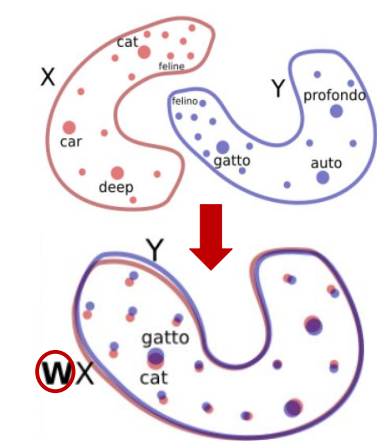 |
Learning translations between different languages has drawn a lot of focus recently. In this work, we examined how we can leverage shared embedding spaces of different languages to learn better translations overall. |
 |
This project revolves around the design of a ball-balancing plate and the anaylsis & implementation of different control algorithms. The thesis describes the entire design process: The CAD-design of the contraption, the dynamical & mechanical analysis, the control design & analysis, the microcontroller implementation, and experimental verification. |
|
Yet another Jon Barron website. |